import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np from nltk.corpus import stopwords from nltk.util import ngrams from sklearn.feature_extraction.textimport CountVectorizer from collections import defaultdict from collections import Counter plt.style.use('ggplot') stop=set(stopwords.words('english')) import re from nltk.tokenize import word_tokenize import gensim import string from keras.preprocessing.textimport Tokenizer from keras.preprocessing.sequence import pad_sequences from tqdm import tqdm from keras.models import Sequential from keras.layers import Embedding, LSTM, Dense, SpatialDropout1D from keras.initializers import Constant from sklearn.model_selection import train_test_split from keras.optimizers import Adam
1 2
import nltk nltk.download("stopwords")
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
True
1
import os
1 2 3
tweet = pd.read_csv('/content/drive/MyDrive/kaggle/tweetDisater/data/train.csv') test = pd.read_csv('/content/drive/MyDrive/kaggle/tweetDisater/data/test.csv') tweet.head(3)
id
keyword
location
text
target
0
1
NaN
NaN
Our Deeds are the Reason of this #earthquake M...
1
1
4
NaN
NaN
Forest fire near La Ronge Sask. Canada
1
2
5
NaN
NaN
All residents asked to 'shelter in place' are ...
1
1 2 3
x = tweet.target.value_counts() sns.barplot(x.index, x) plt.gca().set_ylabel('samples')
/usr/local/lib/python3.6/dist-packages/seaborn/_decorators.py:43: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.
FutureWarning
Text(0, 0.5, 'samples')
결과를 보니까 class 0(No Disaster)이 class 1(disaster tweets)보다 더 많네요.
Exploratory Data Analysis of tweets
Number of characters in tweets
1 2 3 4 5 6 7 8 9
fig, (ax1, ax2) = plt.subplots(1,2,figsize=(10,5)) #figsize = 그림의 가로 세로 인치 단위 tweet_len = tweet[tweet['target'] == 1]['text'].str.len() ax1.hist(tweet_len, color='red') ax1.set_title('disater tweets') tweet_len = tweet[tweet['target']==0]['text'].str.len() ax2.hist(tweet_len, color='green') ax2.set_title('Not disaster tweets') fig.suptitle('Character in tweets') plt.show()
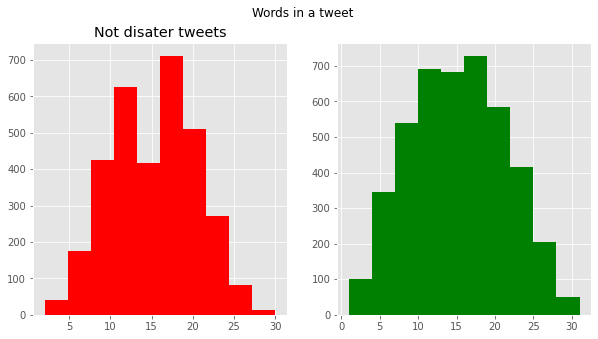
Number of words in a tweet
1 2 3 4 5 6 7 8 9
fig, (ax1, ax2) = plt.subplots(1,2, figsize=(10,5)) #두개 그래프 설정을 한번에 subplots tweet_len = tweet[tweet['target']==1]['text'].str.split().map(lambda x : len(x)) ax1.hist(tweet_len, color='red') ax1.set_title('disater tweets') tweet_len = tweet[tweet['target']==0]['text'].str.split().map(lambda x: len(x)) ax2.hist(tweet_len,color='green') ax1.set_title('Not disater tweets') fig.suptitle('Words in a tweet') plt.show()
Average word length in a tweet
1 2 3 4 5 6 7 8
fig, (ax1, ax2) = plt.subplots(1,2,figsize=(10,5)) word=tweet[tweet['target']==1]['text'].str.split().apply(lambda x : [len(i) for i inx]) sns.distplot(word.map(lambda x : np.mean(x)), ax = ax1, color='red') # 막대 그래프 + mean값으로 선 ax1.set_title('disaster') word = tweet[tweet['target']==0]['text'].str.split().apply(lambda x : [len(i) for i inx]) sns.distplot(word.map(lambda x : np.mean(x)), ax = ax2, color = 'green') ax2.set_title('Not disaster') fig.suptitle('Average word lentgh in a tweet')
/usr/local/lib/python3.6/dist-packages/seaborn/distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
/usr/local/lib/python3.6/dist-packages/seaborn/distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
Text(0.5, 0.98, 'Average word lentgh in a tweet')
1 2 3 4 5 6 7 8
def create_corpus(target): corpus=[] for x in tweet[tweet['target']==target]['text'].str.split(): for i in x: corpus.append(i) return corpus #자연언어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합
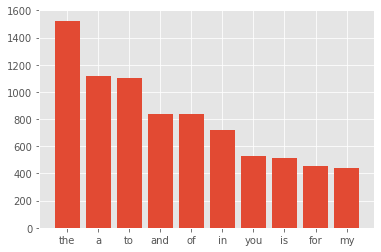
Common stopwords in tweets
stopword(불용어) : 갖고 있는 데이터에서 유의미한 단어 토큰만을 선별하기 위해서는 큰 의미가 없는 단어 토큰을 제거하는 작업이 필요함. 여기서 큰 의미가 없다라는 것은 자주 등장하지만 분석을 하는 것에 있어서는 큰 도움이 되지 않는 단어들을 말함.
class 0 부터 분석
1 2 3 4 5 6 7 8 9
corpus = create_corpus(0)
dic = defaultdict(int) # 디폴트 값이 int인 딕셔너리. for word in corpus: if word in stop: dic[word]+=1
top = sorted(dic.items(), key=lambda x :x [1], reverse = True) [:10]
1 2
x,y = zip(*top) plt.bar(x,y)
<BarContainer object of 10 artists>
1 2 3 4 5 6 7 8 9 10 11 12
corpus = create_corpus(1)
dic = defaultdict(int) # 디폴트 값이 int인 딕셔너리. for word in corpus: if word in stop: dic[word]+=1
top = sorted(dic.items(), key=lambda x :x [1], reverse = True) [:10]
x,y = zip(*top) plt.bar(x,y)
<BarContainer object of 10 artists>
Analyzing punctuations
1 2 3 4 5 6 7 8 9 10 11 12
plt.figure(figsize=(10,5)) corpus = create_corpus(1)
dic = defaultdict(int) importstring special = string.punctuation for i in (corpus) : if i in special : dic[i]+=1
x,y = zip(*dic.items()) plt.bar(x,y)
<BarContainer object of 18 artists>
1 2 3 4 5 6 7 8 9 10 11 12
plt.figure(figsize=(10,5)) corpus = create_corpus(0)
dic = defaultdict(int) importstring special = string.punctuation for i in (corpus) : if i in special : dic[i]+=1
x,y = zip(*dic.items()) plt.bar(x,y, color = 'green')
<BarContainer object of 20 artists>
Common words?
1 2 3 4 5 6 7 8
counter = Counter(corpus) most = counter.most_common() x = [] y = [] forword, count in most [:40]: if(word not in stop) : x.append(word) y.append(count)
1
sns.barplot(x=y, y=x)
<matplotlib.axes._subplots.AxesSubplot at 0x7f8bb4990cc0>
Ngram analysis
bigram (n=2)
1 2 3 4 5 6 7
def get_top_tweet_bigrams(corpus, n = None): vec = CountVectorizer(ngram_range = (2,2)).fit(corpus) bag_of_words = vec.transform(corpus) sum_words = bag_of_words.sum(axis=0) words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()] words_freq = sorted(words_freq, key = lambda x: x[1], reverse = True) return words_freq[:n]